五类强大的概率分布介绍
R编程语言已经成为统计分析中的事实标准。但在这篇文章中,我将告诉你在Python中实现统计学概念会是如此容易。我要使用Python实现一些离散和连续的概率分布。虽然我不会讨论这些分布的数学细节,但我会以链接的方式给你一些学习这些统计学概念的好资料。在讨论这些概率分布之前,我想简单说说什么是随机变量(random variable)。随机变量是对一次试验结果的量化。 基础理论文章来源
[TOC]
二项分布(Binomial Distribution)
举个例子,一个表示抛硬币结果的随机变量可以表示成 Python X = {1 如果正面朝上,2 如果反面朝上} 随机变量是一个变量,它取值于一组可能的值(离散或连续的),并服从某种随机性。随机变量的每个可能取值的都与一个概率相关联。随机变量的所有可能取值和与之相关联的概率就被称为概率分布(probability distributrion)。
我鼓励大家仔细研究一下scipy.stats模块。
概率分布有两种类型:离散(discrete)概率分布和连续(continuous)概率分布。
离散概率分布也称为概率质量函数(probability mass function)。离散概率分布的例子有伯努利分布(Bernoulli distribution)、二项分布(binomial distribution)、泊松分布(Poisson distribution)和几何分布(geometric distribution)等。
连续概率分布也称为概率密度函数(probability density function),它们是具有连续取值(例如一条实线上的值)的函数。正态分布(normal distribution)、指数分布(exponential distribution)和β分布(beta distribution)等都属于连续概率分布。
若想了解更多关于离散和连续随机变量的知识,你可以观看可汗学院关于概率分布的视频。
二项分布(Binomial Distribution)
服从二项分布的随机变量X表示在n个独立的是/非试验中成功的次数,其中每次试验的成功概率为p。

E(X) = np, Var(X) = np(1−p)
如果你想知道每个函数的原理,你可以在IPython笔记本中使用help file命令。 E(X)表示分布的期望或平均值。
键入stats.binom?了解二项分布函数binom的更多信息。
二项分布的例子:抛掷10次硬币,恰好两次正面朝上的概率是多少?
假设在该试验中正面朝上的概率为0.3,这意味着平均来说,我们可以期待有3次是硬币正面朝上的。我定义掷硬币的所有可能结果为k = np.arange(0,11):你可能观测到0次正面朝上、1次正面朝上,一直到10次正面朝上。我使用stats.binom.pmf计算每次观测的概率质量函数。它返回一个含有11个元素的列表(list),这些元素表示与每个观测相关联的概率值。


您可以使用.rvs函数模拟一个二项随机变量,其中参数size指定你要进行模拟的次数。我让Python返回10000个参数为n和p的二项式随机变量。我将输出这些随机变量的平均值和标准差,然后画出所有的随机变量的直方图。


##泊松分布(Poisson Distribution)
一个服从泊松分布的随机变量X,表示在具有比率参数(rate parameter)λ的一段固定时间间隔内,事件发生的次数。参数λ告诉你该事件发生的比率。随机变量X的平均值和方差都是λ。
 E(X) = λ, Var(X) = λ
E(X) = λ, Var(X) = λ
泊松分布的例子:已知某路口发生事故的比率是每天2次,那么在此处一天内发生4次事故的概率是多少?
让我们考虑这个平均每天发生2起事故的例子。泊松分布的实现和二项分布有些类似,在泊松分布中我们需要指定比率参数。泊松分布的输出是一个数列,包含了发生0次、1次、2次,直到10次事故的概率。我用结果生成了以下图片。

 你可以看到,事故次数的峰值在均值附近。平均来说,你可以预计事件发生的次数为λ。尝试不同的λ和n的值,然后看看分布的形状是怎么变化的。
你可以看到,事故次数的峰值在均值附近。平均来说,你可以预计事件发生的次数为λ。尝试不同的λ和n的值,然后看看分布的形状是怎么变化的。
现在我来模拟1000个服从泊松分布的随机变量。


足球比赛概率研究
泊松分布结合历史数据,可以计算足球比赛中可能的进球数。 使用简单的泊松分布公式计算任何给定的足球比赛得分或结果的概率,提高您的投注水平。请继续阅读,了解更多。
泊松分布是一个数学概念,将平均值换算成可变结果的概率。例如,曼城可能每场比赛平均进1.7球。将此信息输入泊松公式中,将显示此平均值相当于曼城在18.3%的时间里进0球,31%的时间进1球,26.4%的时间进2球,15%的时间进3球。
【案例】计算结果的概率
在使用泊松计算可能的赛果前,我们需要计算在比赛中各队可能的平均进球数。得出的平均值用于判断各队的“进攻实力”和“防守实力”,然后两相比较。
计算进攻和防守实力时,选择代表性数据范围非常重要。如果范围太大,数据将偏离队伍目前的实力。如果范围太小,异常值会影响数据的准确性。2015/16 EPL赛季各队的38场比赛为应用泊松分布提供了足够的样本量。
[重点]一旦知道如何计算结果概率,您可以将您的结果与博彩公司的赔率进行比较,从而发现价值。
如何计算进攻实力
根据上一赛季的赛果计算进攻实力时,首先要确定每支球队在主场和在客场的平均进球数。
使用上一赛季的总进球数除以比赛场数进行计算:
- 主场赛季进球数/比赛场数(赛季内)
- 客场赛季进球数/比赛场数(赛季内)
在2015/16英超联赛赛季,主场进球数与比赛场数之比为567/380,客场则为459/380,主场平均进球数为1.492,客场则为1.207。
- 主场平均进球数:1.492
- 客场平均进球数:1.207
上述平均值与球队平均值之差构成球队的进攻实力。
如何计算防守实力
我们还需要知道球队的平均输球数。这只需将上述数字互换位置就可以(因为主队进球数将等于客队输球数):
- 主场平均输球数:1.207
- 客场平均输球数:1.492
上述平均值与球队平均值之差构成球队的防守实力。
我们现在可以使用上面的数字来计算托特纳姆和埃弗顿在2017年3月1日的比赛的攻击实力和防守实力。
#####预测托特纳姆热刺的进球数 计算托特纳姆的进攻实力:
步骤1使用上一赛季主队主场进球数(托特纳姆:35球)除以主场比赛场数(35⁄19):1.842。 步骤2:使用此值除以赛季每场比赛平均主队进球数(1.842⁄1.492),得出“进攻实力”:1.235。 (35⁄19) / (567⁄380) = 1.235
计算斯埃弗顿的防守实力:
步骤1使用上一赛季客队客场输球数除(埃弗顿:25球)除以客场比赛场数(25⁄19):1.315。 步骤2:使用此值除以客队每场比赛平均输球数(1.315⁄1.492),得出“防守实力”:0.881。 (25⁄19) / (567⁄380) = 0.881
我们现在可以使用下面的公式来计算托特纳姆的得分数目(这是通过将托特纳姆的进攻强度乘以埃弗顿的防守实力和英超的平均主球数来完成的): 1.235 x 0.881 x 1.492 = 1.623 预测埃弗顿的进球数
要计算埃弗顿可能的进球数,只需使用上述公式,不过需要将主场平均进球数替换为客场平均进球数。
埃弗顿的进攻实力: (24⁄19) / (459⁄380) = 1.046 托特纳姆的防守实力: (15⁄19) / (459⁄380) = 0.653 以同样的方式我们预测了托特纳姆的进球数,我们可以计算埃弗顿可能得分的进球数(通过将埃弗顿的进攻强度乘以托特纳姆的防守实力和英超的平均进球数): 1.046 x 0.653 x 1.207 = 0.824 泊松分布博彩 – 预测多个比赛结果
当然,比赛的分数不会是1.623 vs. 0.824,这只是平均数。泊松分布是法国数学家西莫恩·德尼·泊松发明的公式,允许我们使用这些数据计算各球队的各种进球结果的概率。
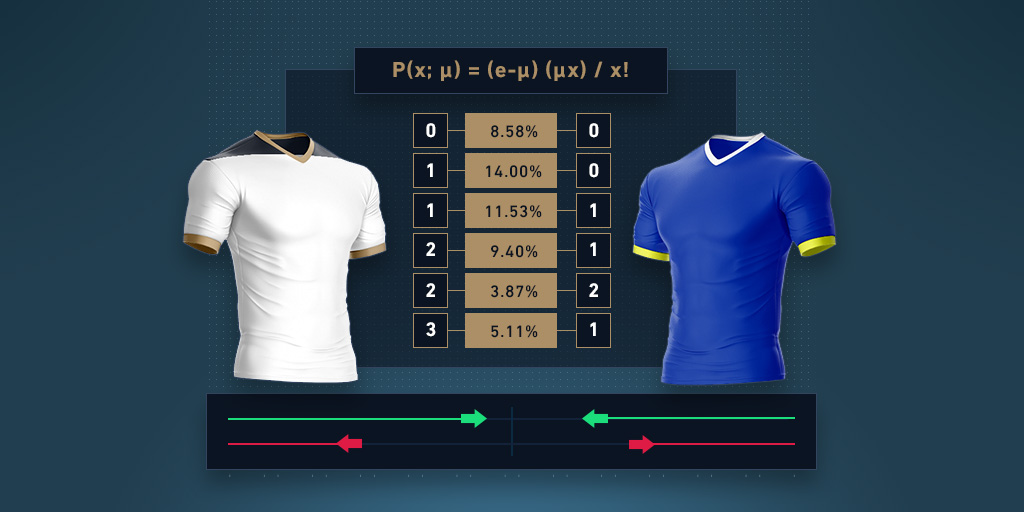
泊松分布公式: P(x; μ) = (e-μ) (μx) / x! 但是,我们可以使用泊松分布计算器等在线工具,完成大部分计算。
我们只需在随机变量(x)类别中输入不同的进球结果(0-5),在平均胜率中输入球队得分可能性(例如,托特纳姆为1.623),计算器将计算该分数的机率。
托特纳姆vs. 埃弗顿的泊松分布
进球 0 1 2 3 4 5 托特纳姆 19.73% 32.02% 25.99% 14.03% 5.07% 1.85% Everton 43.86% 36.14% 14.89% 4.09% 0.84% 0.14%
此示例显示,托特纳姆不得分的机率为19.73%,但是他们进1球的机率为32.02%,进2球的机率为25.99%。另一方面,埃弗顿不得分的机率为43.86%,进1球的机率为36.14%,进2球的机率为14.89%。希望球队进五球?托特纳姆的概率是1.85%,埃弗顿的概率是0.14%。
由于两个分数都是独立的(数学上讲),可以看出预期比分为1-0。如果将两个概率相乘,您将得出比分为1-0的概率为0.1400或14.00%。
现在您已了解如何计算结果概率,您可以将您的结果与博彩公司的赔率进行比较,看看是否有机可乘。
#####将估计的机率转换为赔率 【重要】一旦计算了每个结果的机率,可以将其转换成赔率,并将该赔率与博彩公司的赔率进行比较,以找到有价值的投注。
上面的例子告诉我们,当应用泊松分布公式时,1-1平局发生的机率为11.53%。但是如何你想要投注“平局”而不是单个得分结果,该怎么做?您需要计算 所有 不同的平局比分—— 0-0、1-1、2-2、3-3、4-4、5-5等等的概率。 只需计算所有可能的平局组合的概率,然后把他们加起来。将得出发生平局的机率,无论分数是多数。
当然,实际上有无数种平局可能性(例如两队各进10球),但是5-5以上平局的机率很小,在模型中可以忽略不计。
拿托特纳姆vs. 埃弗顿作为例子来说,结合所有的平局给出概率0.2474或24.74%,将得出真实的赔率为4.05。
#####泊松分布的局限
泊松分布是简单的预测模型,不考虑大量因素。情景因素——例如俱乐部情况、比赛状态等——和转会窗期间各队队员变更的主观评估被完全忽略。
在这种情况下,上述泊松公式计算未能量化埃弗顿的新教练罗纳德·科曼对球队可能产生的任何影响。它也没有考虑托特纳姆潜在的疲劳状态,因为这一比赛接近定期举行的欧罗巴联赛。
此外还忽略了关联因素:例如被广泛认可的球场情结,显示某些比赛有得高分或低分的趋势。
这些都是低级联赛中特别重要的领域,可以给予投注者对阵博彩公司的优势。由于现代博彩公司拥有专业知识和资源,在诸如英超联赛等大型联赛中投注者难以获得优势。
想要将泊松分布应用于足球博彩?来Pinnacle(平博),畅享英超联赛最佳赔率和最高投注限额。
案例延伸
##正态分布(Normal Distribution)
正态分布是一种连续分布,其函数可以在实线上的任何地方取值。正态分布由两个参数描述:分布的平均值μ和方差σ2 。
 E(X) = μ, Var(X) = σ2
E(X) = μ, Var(X) = σ2

 正态分布的取值可以从负无穷到正无穷。你可以注意到,我用stats.norm.pdf得到正态分布的概率密度函数。
正态分布的取值可以从负无穷到正无穷。你可以注意到,我用stats.norm.pdf得到正态分布的概率密度函数。
##β分布(Beta Distribution)
β分布是一个取值在 [0, 1] 之间的连续分布,它由两个形态参数α和β的取值所刻画。
 β分布的形状取决于α和β的值。贝叶斯分析中大量使用了β分布。
β分布的形状取决于α和β的值。贝叶斯分析中大量使用了β分布。

 当你将参数α和β都设置为1时,该分布又被称为均匀分布(uniform distribution)。尝试不同的α和β取值,看看分布的形状是如何变化的。
当你将参数α和β都设置为1时,该分布又被称为均匀分布(uniform distribution)。尝试不同的α和β取值,看看分布的形状是如何变化的。
##指数分布(Exponential Distribution)
指数分布是一种连续概率分布,用于表示独立随机事件发生的时间间隔。比如旅客进入机场的时间间隔、打进客服中心电话的时间间隔、中文维基百科新条目出现的时间间隔等等。
 我将参数λ设置为0.5,并将x的取值范围设置为 $[0, 15]$ 。
我将参数λ设置为0.5,并将x的取值范围设置为 $[0, 15]$ 。

 接着,我在指数分布下模拟1000个随机变量。scale参数表示λ的倒数。函数np.std中,参数ddof等于标准偏差除以 $n-1$ 的值。
接着,我在指数分布下模拟1000个随机变量。scale参数表示λ的倒数。函数np.std中,参数ddof等于标准偏差除以 $n-1$ 的值。


结语(Conclusion) 概率分布就像盖房子的蓝图,而随机变量是对试验事件的总结。我建议你去看看哈佛大学数据科学课程的讲座,Joe Blitzstein教授给了一份摘要,包含了你所需要了解的关于统计模型和分布的全部。